Netty(二)线程模型与 Bytebuf
Netty(二)线程模型与 Bytebuf
ServerBootStrap 中的 EventLoopGroup
ServerBootStrap 实际上内部是两个 group,解释:
Most of the times using the same group for accepting and handling the accepted connections is working out quite well and so allows you to save some threads. The only time when you may not want to do this is if the handling logic of the accepted connections will keep the EventLoops so busy that you are not able to accept fast enough.
Vert.x 是一个基于 Netty 的框架,但是其初始化是将一个线程组(EventLoopGroup)同时用于 boss 与 worker。Norman回答到,这种方法大多数时候都挺不错,并且节省了一些线程。我认为这里说的节省了的线程是 boss 线程,在没有新的连接进来的时候可以参与到 handler 的任务中。然而,当 handler 要处理的任务消耗太多 CPU 时间时,EventLoopGroup 中的所有 EventLoop,也就是线程,会全都忙于处理任务,不能很快地、甚至无法 accept 新进来的连接。
对于 boss EventLoopGroup,什么情况下使用超过一个线程?
在构造函数中可以选择线程数:NioEventLoopGroup(threadsAmount)。但是,既然 boss group 的职责只是接受 accept 新连接并且分发,按照 Proactor 的模型,一个线程足矣。当一个 EventLoopGroup 被多个 ServerBoostrap 分享,则按需增加线程。
EventLoopGroup 默认线程数
如果在 EventLoopGroup 初始化时没有指定线程数,则由以下的静态初始块设置默认线程数。代码出自MultithreadEventLoopGroup.java 第 40 行。
1 | static { |
ChannelHandler 与 EventLoopGroup 中的线程
用自己语言更具体解释一下“Netty 4中的Handler处理在IO线程中,如果Handler处理中有耗时的操作(如数据库相关),会让IO线程等待,影响性能。”
我们之前已经阐明了不要阻塞当前 I/O 线程的重要性。我们再以另一种方式重申一次:“永远不要将一个长时间运行的任务放入到执行队列中,因为它将阻塞需要在同一线程执行的任何其他任务。” 如果必须要进行阻塞调用或者执行长时间运行的任务,我们建议使用一个专门的 EventExecutor。(见 6.2.1 节的“ChannelHandler 的执行和阻塞”)。
– 摘自 Netty in Action P96
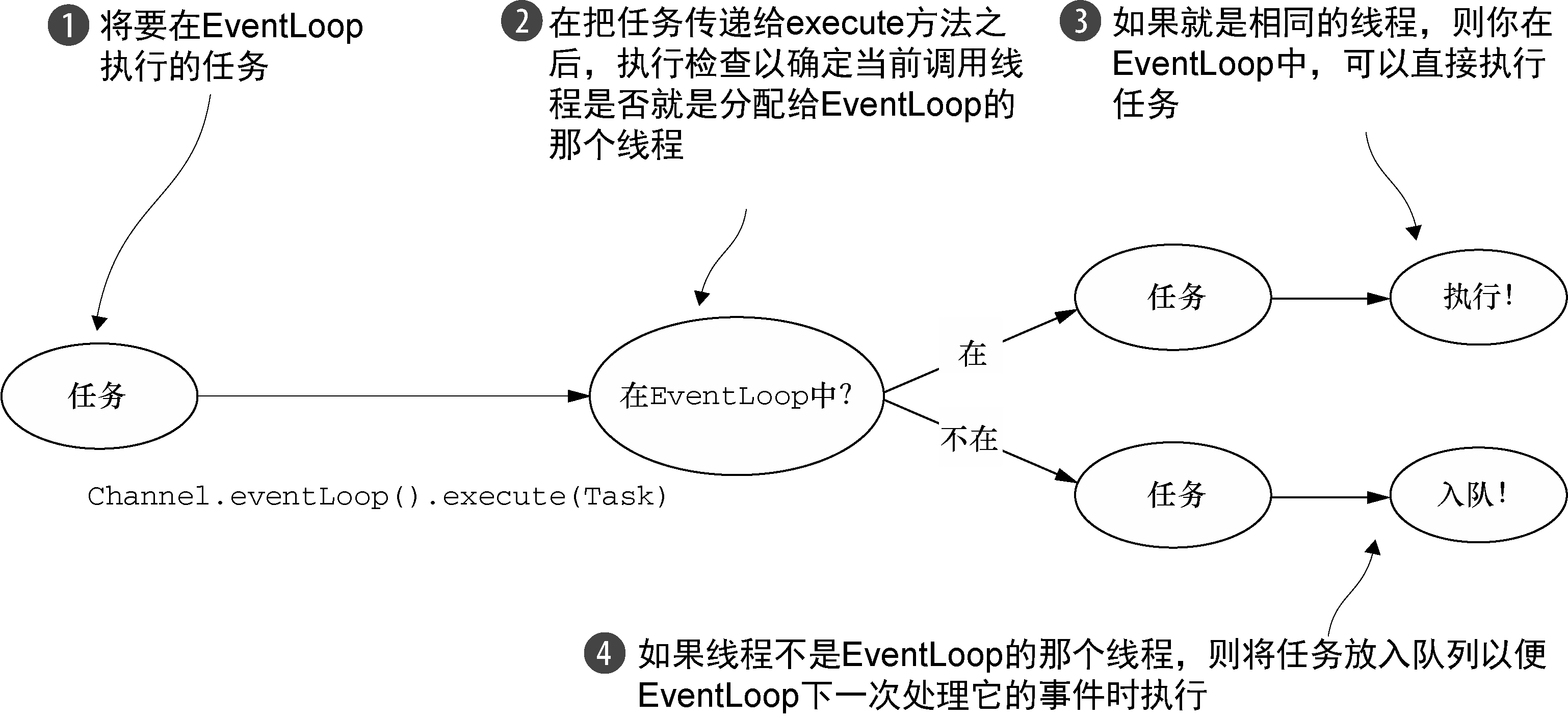
总结一下,EventLoop 中的线程又被称为 I/O 线程,一个 Channel 中的所有事件(出站/入站)都只会被其所绑定的这个 I/O 线程处理。一个 Channel 永远一个 EventLoop I/O 线程绑定,而一个 I/O 线程则可能被分配给多个 Channel。如果这个 I/O 线程陷入执行一个 CPU 时间耗时长的任务,所有与之关联的 Channel 中的任务都会被搁置。
源码如下,来自 AbstractChannelHandlerContext.java#write()。在执行写任务时,先判断了执行线程是否是该 Channel 绑定的线程,如果是则交由执行,如果不是则新增一个 WriteTask。
1 | EventExecutor executor = next.executor(); |
Netty 3 中的不和谐
这里需要注意一下,某个给定的 EventLoop 中的所有事件,都是由同一个线程处理。这是 Netty 4 对 Netty 3 的改进。在 Netty 3 中,出站事件可以由 I/O 线程执行,也可以由调用线程执行,这就使得 Race Condition 成为可能,比如一个 Channel 上的 Channel.write() 被同时调用时。
官方 Wiki 上有一个 Thread model 的页面是针对 Netty 3 的过期信息,可以看看当时开发者对这个问题的考量。
Bytebuf 源码
UnpooledHeapByteBuf 基于 JVM 堆内存进行内存分配,每次使用,都从头创建一个新的 实例。性能:相比堆外内存的分配和释放,成本仍然更低一些。
UnpooledHeapByteBuf 拥有三个成员变量:
1 | private final ByteBufAllocator alloc; // 用于分配内存 |
注意这里为了提升性能与位操作,Netty 并没有直接使用原生的 ByteBuffer,而是使用数组作为缓存。